#Scraping government website data
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





trefle-applications-expert-excel
Trèfle Applications : votre allié du développement digital
28 posts
Fun Fact
Tumblr Inc. is funded by 13 investors.
Text
How Web Scraping Helps In Extracting Government And Public Sector Data?

Along with the growth in technology, big data and analytics are undeniably no less crucial these days. It applies to business companies, healthcare, and the administration. Web scraping is the process of harvesting essential data from the internet reservoir; therefore, it can obtain this vital information. Changing public sector and government research science requires better data for decision-makers to make the right choices, and these are people like policymakers and analysts, among others. However, on digital platforms, a lot of information is generated, which needs to be clarified when trying to filter or sort it all out. Therefore, web scraping provides a means of collecting data more efficiently and making research more creative and rapidly performed.
What is Government and Public Data Scraping?
Data scraping, or web scraping, is using a digital tool to collect information from websites and online databases automatically. Dream of no more need to visit websites to copy all important data – let a robot do it. This tool collects data from websites like government rules, public reports, or price tags. People utilize data scraping for research purposes, such as examining legislation or analyzing market patterns. It is an excellent way to get information rapidly (all you need to understand various topics) and use it to understand any subject better.
Nevertheless, a handful of points are worth considering when performing web scraping government sites. It is essential to follow the rules and laws about using online information. For instance, certain websites may not allow scraping; thus, you should adhere to them by any means. Furthermore, we must handle personal data cautiously and avoid undesired behaviors as much as possible. So, while data scraping is an effective tool, it must be used safely and politely.
Scraping Data from Government Sources
Scraping government website data means using special tools or programs to collect information from official government websites, databases, or online portals. Government bodies, such as data storehouses, are especially information-supplier entities, such as laws, public records, budgets, and statistics. Without that data, data scientists and analysts, which are not customer-friendly for regular people, can be equipped with vital information, monitor the government, and check public policies and efficiency.
Scraping government websites involves retrieving data from data providers or sources such as government websites.
Summary
What Kind of Data Can You Get From Government Websites:
Laws and Rules: This includes the texts of laws, rules, and policies.
Public Records: Things like birth certificates, property ownership, and court case details.
Financial Data: Budgets, economic stats, and tax details.
People and Society: Census info, health numbers, and education stats.
Environment: Weather data, pollution info, and maps.
Public Opinion: Surveys, polls, and comments from the public.
From Public Organizations
Business Data: Details about registered businesses and professional licenses.
Regulatory Docs: Reports and documents that businesses have to submit.
Safety and Infrastructure: Crime rates, emergency services, and transportation details.
Types of Data Scraped from Government Websites
Remember, the kind of data you can find might differ depending on where you are or which part of the government you're looking at. When obtaining data from various sources, adhering to any restrictions or norms is critical.
Laws and Rules
Laws and Regulations: These are like the rulebooks that the government follows. They contain the actual texts of laws and rules that the government sets.
Policy Papers: These act as the government's master data. They're official documents outlining the government's intentions and strategies for addressing various issues.
Property Records: These records tell us about properties in an area, such as who owns them, how much they're worth, and how they're being used.
Court Records: This is information about legal cases, like who's involved, what the case is about, and when the court dates are.
Money Matters
Budgets and Spending: Those documents basically show us where the government plans to spend its money. Allocation of funds, detailing expenditures on sectors such as education, infrastructure, and healthcare while also disclosing the destinations of the funds.
Economic Stats: As for economic stats, they are a quick outline of how the economy is doing. They tell us if people find jobs easily and if prices are going up or down. It's a way to see if the economy is healthy or if some problems need fixing.
Taxes: Here, you can find information about how much tax people and businesses have to pay, what forms they need to fill out, and any rules about taxes.
People and Society
Census Data: This gives us information about the people living in a place, like how many people live there, their ages, and other demographics.
Health Stats: These tell us about people's health, such as whether there's a lot of flu or how many people have been vaccinated.
Education: This part tells us about schools, including how students are doing in their classes, how many students graduate, and what resources the schools have.
Climate Info: This is all about the weather and climate in an area, such as whether it's usually hot or cold or if it rains a lot
Environmental Assessments: These give us details about the environment, like how clean the air and water are and if there are any protected areas.
Maps and Geospatial Data: These are digital maps that show where things are located, such as parks, roads, or buildings.
Public Opinion
Surveys and Polls: These are questionnaires that ask people what they think about different things. They might ask who they voted for in an election or what they think about a new law. It is a way for people to share their opinions and for others to understand what's important to them.
Public Comments: This is feedback from people about government plans or projects. It's like when people write to say what they think about a new road or park.
Business Licenses: This tells us about businesses in an area, like what they do and if they have the proper licenses to operate.
Professional Licenses: These are licenses that people need to work in specific jobs, like doctors or lawyers.
Regulatory Info: This is paperwork that businesses or organizations have to fill out to show they're following the rules set by the government.
Crime Stats: This tells us about crime in an area, such as how many crimes are happening and what kind.
Emergency Services: This is information about services like fire departments or ambulances, like how quickly they respond to emergencies.
Transport Info: This gives us details about getting around, like traffic conditions or bus schedules.
Infrastructure: This is about public projects like building roads or schools, telling us what's being built and when it will be done.
Scraping Data from the Public Sector
Scraping data from the public sector is collecting information from government websites or sites that receive money from the government. This information can be helpful for researching, public sector data analytics, or ensuring that things are open and transparent for everyone. Businesses scrape public sector data to stay updated with the latest updates.
By scraping different types of data from the public sector, researchers, analysts, or even regular people can learn a lot, make better decisions, perform public sector data analytics, and monitor what the government and public organizations are doing.
Laws and Regulations
Texts of Laws, Regulations, and Policies: This is where you can find the actual words of laws made by the government. It also includes rules and plans for different areas like traffic, environment, or health.
Public Records
Vital Records: These are essential papers that tell us about significant events in people's lives, such as when they were born, married, passed away, or divorced.
Property Records: These data tell you about properties, such as who owns them, how much they're worth, and what they're used for.
Court Records: This is information about legal cases, court decisions, and when the next court dates are.
Financial Data
Budgets: These plans show how the government will spend money on different things.
Economic Indicators: These are data that tell us how well the economy is doing, such as whether people have jobs or if prices are going up.
Tax Information: This is about taxes, like how much people or businesses have to pay and how the government uses that money.
Demographic Data
Census Data: This is information from the national headcount of people, showing things like age, where people live, and family size.
Health Statistics: This is data about health issues, like outbreaks, vaccination rates, or hospitals.
Education Data: This tells us about schools, how well students are doing, and what resources are available.
Environmental Data
Climate Information: This is about the weather and climate, like temperatures or weather patterns.
Environmental Assessments: These are studies about how people affect the environment, pollution, and efforts to protect nature.
Geospatial Data: This is like digital maps showing geographical information, like boundaries or landmarks.
Public Opinion
Surveys and Polls: These are the results of asking people questions to determine their thoughts on different topics.
Public Comments: People's feedback or opinions on government plans or projects.
Public Organizations
Business Licenses: This is information about businesses, such as their name, address, type, and whether they have a license.
Professional Licenses: This is about licenses for jobs like doctors, lawyers, or engineers, showing if they're allowed to practice and if they've had any issues.
Regulatory Filings
Professional Licenses: This is about licenses for jobs like doctors, lawyers, or engineers, showing if they're allowed to practice and if they've had any issues.
Reports and Documents: These are papers or reports that businesses or people have to give to certain government agencies, like financial reports or environmental studies.
Crime Statistics: These data tell us about crime, such as the amount or types of crimes committed.
Emergency Services Data: This is information about services like fire or ambulance services, such as how quickly they respond to emergencies.
Transportation Information: This tells us about getting around, like traffic, roads, public transit, or significant construction projects.
Benefits of Web Scraping in the Government and Public Sector
Companies should be responsible enough to choose the data they believe brings greater value to a specific context at that time. There are various benefits of web scraping government sites and public sector data:
Transparency and Accountability
When we perform web scraping government sites, we can see what the government is doing more clearly. Government and public sector data analytics helps keep them accountable because people can see where money is being spent and what decisions are being made.
Informed Decision-Making
Businesses scrape government websites and public sector data to get access to large datasets that help researchers, policymakers, and businesses make better decisions. For example, they can determine whether a new policy is working or understand economic trends to plan for the future.
Research and Analysis
The modern approach to scrape public sector data and government website data can be utilized by professionals and scientists to learn more about health, education, and the environment. This allows us to learn more about these subjects and identify ways to enhance them.
Public Services and Innovation
With public sector data analytics and web scraping government sites, developers can create new apps or sources of information that make life easier for people. For example, maps showing public transportation routes or directories for community services.
Economic Development
Businesses can use government economic data to make plans by ensuring success of their business. This can attract more investment because investors can see where there are good opportunities.
Public Engagement and Participation
When businesses extract public sector data and government website data, People can join conversations about community matters when they can easily understand government information. This makes democracy stronger by letting more people share their thoughts and shape what happens in their area.
Conclusion
Web scraping is increasingly seen as a valuable tool for extracting data, particularly as governments and public sectors adapt to the digital era. One of the most critical factors in current governance is no longer the line about open data projects with performing web scraping government sites.
Collaborating with enterprises data scraping like iweb Scraping is the way toward a future course of events where data-driven governance is the leading force. Thus, the public sector is more informed, transparent, and accountable. Scraping data from the internet can be viewed as a powerful tool for governmental institutions that enables them to collect a massive amount of essential information in a relatively short time. To put it categorically, web scraping is a valuable tool that the government should embrace as its friend. Companies that collect data, like iWeb Scraping services, are at the forefront of innovation and provide improved and new methods of data collecting that benefit all parties. Nevertheless, some challenges can come up often, but this web scraping company remains relevant to the government and public sector institutions during their data scraping process. The process of scraping public sector data and government websites is gathered with diligence and ethical consideration to help policymakers make more informed decisions and improve their services.
0 notes
Text

Ellipsus Digest: March 18
Each week (or so), we'll highlight the relevant (and sometimes rage-inducing) news adjacent to writing and freedom of expression.
This week: AI continues its hostile takeover of creative labor, Spain takes a stand against digital sludge, and the usual suspects in the U.S. are hard at work memory-holing reality in ways both dystopian and deeply unserious.
ChatGPT firm reveals AI model that is “good at creative writing” (The Guardian)
... Those quotes are working hard.
OpenAI (ChatGPT) announced a new AI model trained to emulate creative writing—at least, according to founder Sam Altman: “This is the first time i have been really struck by something written by AI.” But with growing concerns over unethically scraped training data and the continued dilution of human voices, writers are asking… why?
Spoiler: the result is yet another model that mimics the aesthetics of creativity while replacing the act of creation with something that exists primarily to generate profit for OpenAI and its (many) partners—at the expense of authors whose work has been chewed up, swallowed, and regurgitated into Silicon Valley slop.
Spain to impose massive fines for not labeling AI-generated content (Reuters)
But while big tech continues to accelerate AI’s encroachment on creative industries, Spain (in stark contrast to the U.S.) has drawn a line: In an attempt to curb misinformation and protect human labor, all AI-generated content must be labeled, or companies will face massive fines. As the internet is flooded with AI-written text and AI-generated art, the bill could be the first of many attempts to curb the unchecked spread of slop.
Besos, España 💋
These words are disappearing in the new Trump administration (NYT)
Project 2025 is moving right along—alongside dismantling policies and purging government employees, the stage is set for a systemic erasure of language (and reality). Reports show that officials plan to wipe government websites of references to LGBTQ+, BIPOC, women, and other communities—words like minority, gender, Black, racism, victim, sexuality, climate crisis, discrimination, and women have been flagged, alongside resources for marginalized groups and DEI initiatives, for removal.
It’s a concentrated effort at creating an infrastructure where discrimination becomes easier… because the words to fight it no longer officially exist. (Federally funded educational institutions, research grants, and historical archives will continue to be affected—a broader, more insidious continuation of book bans, but at the level of national record-keeping, reflective of reality.) Doubleplusungood, indeed.
Pete Hegseth’s banned images of “Enola Gay” plane in DEI crackdown (The Daily Beast)
Fox News pundit-turned-Secretary of Defense-slash-perpetual-drunk-uncle Pete Hegseth has a new target: banning educational materials featuring the Enola Gay, the plane that dropped the atomic bomb on Hiroshima. His reasoning: that its inclusion in DEI programs constitutes "woke revisionism." If a nuke isn’t safe from censorship, what is?
The data hoarders resisting Trump’s purge (The New Yorker)
Things are a little shit, sure. But even in the ungoodest of times, there are people unwilling to go down without a fight.
Archivists, librarians, and internet people are bracing for the widespread censorship of government records and content. With the Trump admin aiming to erase documentation of progressive policies and minority protections, a decentralized network is working to preserve at-risk information in a galvanized push against erasure, refusing to let silence win.
Let us know if you find something other writers should know about, (or join our Discord and share it there!) Until next week, - The Ellipsus Team xo

619 notes
·
View notes
Text
the more chatgpt combs the idiots of humanity into its fetid drainpipe and scrapes for the diamonds of human creativity like some kind of a grotesque Gollum, the more i think of Bond's line to Q in Skyfall in the National Gallery
"-Or not pulled."
and it's like yeah, true, one day people aren't going to have practical experience in almost anything
but like secondly, this is why a film about Q would be so relevant today. they didn't follow through on the theme from Skyfall with the rest of the Craig Bond films, but going off their convo in the National Gallery the inevitability of time occurred: Q essentially "replaced" Bond (Bond died in NTTD), and the younger generation of Britain, represented by Q, took over without its stalwart steward Bond to mind the gates. The new ideas and changing world that Bond (and Dench's M) were rueful about took precedence.
Now we have monsters made of the tech that was supposed to save us and bring equity - because tech isn't a pure medium. It is made by imperfect men and thus is imperfect.
It would be gratifying in today's world of shitty generative AI, predatory online monitoring, disinformation, deepfake video and audio, unchecked data collection by websites and apps, unrelenting ads, subscriptions, and international election interference - that someone like Q would reflect on the unfurling of his generation's (ours) hopes and dreams.
He would be a great modern Agent protagonist to go up against toxic tech and the unjust surveillance that goes both unaddressed and used with flagrant abandon by governments, corporations, and individuals towards the generation population.
And that, of course, would tie back into his fateful convo with Bond and the humility Q gained as he got older and reflected on the world - and how to protect people, ironically by resurrecting concepts from the derided Old World to save the New.
#james bond#00q#they shoukd make bond a secondary character is movies about Q moneypenny and M (past or future)#**in movies#and make it like the Craig bond younger or flashbacks of him#obviously castibg a young actor or getting a cameo for flashback scenes
30 notes
·
View notes
Text
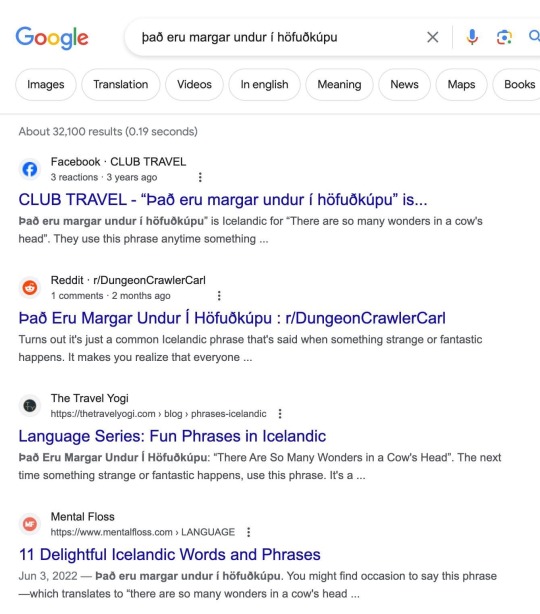
A fascinating discovery in an Icelandic-language Facebook group: the phrase “Það eru margar undur í höfuðkúpu”. A bunch of online articles will teach you this delightful saying and explain that it means “There are many wonders in a cow’s head”. Only, oddly enough, none of the results for the full phrase are Icelandic websites. It’s all blogs, fiction and social media posts by foreigners…
That would be because “Það eru margar undur í höfuðkúpu” is not a real Icelandic saying. Not only is it not a real saying, it’s grammatical nonsense: “margar” is the feminine plural of the word many, but “undur” meaning “wonder” is a neuter word. Moreover, “Það eru margar undur í höfuðkúpu” features absolutely no mention of a cow: it just means “There are many wonder in a skull”.
However, “There are many wonders in a cow’s head” is recognizably a translation of a genuine Icelandic saying - it’s just decidedly not that one. The real saying is “Það er margt skrýtið í kýrhausnum” (literally “There’s a lot of strange stuff in the cow’s head”). Somehow, somewhere along the way, someone had heard there was an Icelandic saying that meant “There are many wonders in a cow’s head” and just ran that back through a machine translation and called it a day - and then a bunch of other websites aped it after them without even a cursory fact-check by anyone who actually knows the language.
Fun fact: I bet the reason the cow disappeared from the machine translation is that the word “höfuðkúpu” happens to contain the letters -kú-, which is coincidentally the accusative and dative of the word kýr. Neural network sees a token it associates with cows in there and just figures yeah, checks out. Likewise, the grammatical error makes some warped sense for a neural network to output: while “undur” the word meaning wonder is a neuter word, many feminine words genuinely end in -ur in the plural.
(Sponsored by the Icelandic government, Icelandic linguistic tech company Miðeind collaborated with OpenAI to make GPT-4 understand and write Icelandic. They contributed a deluge of training data of Icelandic text and reinforcement learning. The results were initially pretty disappointing - because GPT is pre-trained on text scraped from the internet, and the vast majority of purportedly Icelandic text on the internet is machine-translated slop, because there just aren’t enough actual Icelandic speakers and Icelandic websites to drown out all the spam. Very recently, though, they managed to genuinely substantially improve it.)
#iceland#icelandic#don’t believe everything you read about foreign languages on the internet#especially not tiny languages with not enough native speakers to correct all the horseshit
97 notes
·
View notes
Text
By Madge Waggy MadgeWaggy.blogspot.com
December 30, 2024
According to Steven Overly From: www.politico.com The freakout moment that set journalist Byron Tau on a five-year quest to expose the sprawling U.S. data surveillance state occurred over a “wine-soaked dinner” back in 2018 with a source he cannot name.
The tipster told Tau the government was buying up reams of consumer data — information scraped from cellphones, social media profiles, internet ad exchanges and other open sources — and deploying it for often-clandestine purposes like law enforcement and national security in the U.S. and abroad. The places you go, the websites you visit, the opinions you post — all collected and legally sold to federal agencies.
I’m going to alert you to what many are considering to be on of the worst doomsday scenarios for free American patriots. One that apparently not many are prepping for, or even seem to care about.
By now everybody knows that the government ‘alphabet agencies’ including mainly the NSA have been methodically collecting data on us. Everything we do, say, buy and search on the internet will be on permanent data base file by next year. All phone calls now are computer monitored, automatically recorded and stored with certain flag/trigger words (in all languages).
As technology improves, every single phone call will be entirely recorded at meta-data bases in government computer cloud storage, when ‘They’ finish the huge NSA super spy center in Utah. Which means they will be available anytime authorities want to look them up and personally listen for any information reference to any future investigation. Super computer algorithms will pin point search extrapolations of ANY relationship to the target point.
You can rest uneasily, but assured, that in the very near future when a cop stops you and scans your driver license into his computer, he will know anything even remotely ��suspicious’ or ’questionable’ about ALL the recent activities and behavior in your life he chooses to focus upon!
This is the ‘privacy apocalypse’ coming upon us. And you need to know these five devices that you can run to protect your privacy, but you can’t hide from.
When Security Overlaps Freedom
11 notes
·
View notes
Note
Have you considered going to Pillowfort?
Long answer down below:
I have been to the Sheezys, the Buzzlys, the Mastodons, etc. These platforms all saw a surge of new activity whenever big sites did something unpopular. But they always quickly died because of mismanagement or users going back to their old haunts due to lack of activity or digital Stockholm syndrome.
From what I have personally seen, a website that was purely created as an alternative to another has little chance of taking off. It it's going to work, it needs to be developed naturally and must fill a different niche. I mean look at Zuckerberg's Threads; died as fast as it blew up. Will Pillowford be any different?
The only alternative that I found with potential was the fediverse (mastodon) because of its decentralized nature. So people could make their own rules. If Jack Dorsey's new dating app Bluesky gets integrated into this system, it might have a chance. Although decentralized communities will be faced with unique challenges of their own (egos being one of the biggest, I think).
Trying to build a new platform right now might be a waste of time anyway because AI is going to completely reshape the Internet as we know it. This new technology is going to send shockwaves across the world akin to those caused by the invention of the Internet itself over 40 years ago. I'm sure most people here are aware of the damage it is doing to artists and writers. You have also likely seen the other insidious applications. Social media is being bombarded with a flood of fake war footage/other AI-generated disinformation. If you posted a video of your own voice online, criminals can feed it into an AI to replicate it and contact your bank in an attempt to get your financial info. You can make anyone who has recorded themselves say and do whatever you want. Children are using AI to make revenge porn of their classmates as a new form of bullying. Politicians are saying things they never said in their lives. Google searches are being poisoned by people who use AI to data scrape news sites to generate nonsensical articles and clickbait. Soon video evidence will no longer be used in court because we won't be able to tell real footage from deep fakes.
50% of the Internet's traffic is now bots. In some cases, websites and forums have been reduced to nothing more than different chatbots talking to each other, with no humans in sight.
I don't think we have to count on government intervention to solve this problem. The Western world could ban all AI tomorrow and other countries that are under no obligation to follow our laws or just don't care would continue to use it to poison the Internet. Pandora's box is open, and there's no closing it now.
Yet I cannot stand an Internet where I post a drawing or comic and the only interactions I get are from bots that are so convincing that I won't be able to tell the difference between them and real people anymore. When all that remains of art platforms are waterfalls of AI sludge where my work is drowned out by a virtually infinite amount of pictures that are generated in a fraction of a second. While I had to spend +40 hours for a visually inferior result.
If that is what I can expect to look forward to, I might as well delete what remains of my Internet presence today. I don't know what to do and I don't know where to go. This is a depressing post. I wish, after the countless hours I spent looking into this problem, I would be able to offer a solution.
All I know for sure is that artists should not remain on "Art/Creative" platforms that deliberately steal their work to feed it to their own AI or sell their data to companies that will. I left Artstation and DeviantArt for those reasons and I want to do the same with Tumblr. It's one thing when social media like Xitter, Tik Tok or Instagram do it, because I expect nothing less from the filth that runs those. But creative platforms have the obligation to, if not protect, at least not sell out their users.
But good luck convincing the entire collective of Tumblr, Artstation, and DeviantArt to leave. Especially when there is no good alternative. The Internet has never been more centralized into a handful of platforms, yet also never been more lonely and scattered. I miss the sense of community we artists used to have.
The truth is that there is nowhere left to run. Because everywhere is the same. You can try using Glaze or Nightshade to protect your work. But I don't know if I trust either of them. I don't trust anything that offers solutions that are 'too good to be true'. And even if take those preemptive measures, what is to stop the tech bros from updating their scrapers to work around Glaze and steal your work anyway? I will admit I don't entirely understand how the technology works so I don't know if this is a legitimate concern. But I'm just wondering if this is going to become some kind of digital arms race between tech bros and artists? Because that is a battle where the artists lose.
29 notes
·
View notes
Text
Less than three months after Apple quietly debuted a tool for publishers to opt out of its AI training, a number of prominent news outlets and social platforms have taken the company up on it.
WIRED can confirm that Facebook, Instagram, Craigslist, Tumblr, The New York Times, The Financial Times, The Atlantic, Vox Media, the USA Today network, and WIRED’s parent company, Condé Nast, are among the many organizations opting to exclude their data from Apple’s AI training. The cold reception reflects a significant shift in both the perception and use of the robotic crawlers that have trawled the web for decades. Now that these bots play a key role in collecting AI training data, they’ve become a conflict zone over intellectual property and the future of the web.
This new tool, Applebot-Extended, is an extension to Apple’s web-crawling bot that specifically lets website owners tell Apple not to use their data for AI training. (Apple calls this “controlling data usage” in a blog post explaining how it works.) The original Applebot, announced in 2015, initially crawled the internet to power Apple’s search products like Siri and Spotlight. Recently, though, Applebot’s purpose has expanded: The data it collects can also be used to train the foundational models Apple created for its AI efforts.
Applebot-Extended is a way to respect publishers' rights, says Apple spokesperson Nadine Haija. It doesn’t actually stop the original Applebot from crawling the website—which would then impact how that website’s content appeared in Apple search products—but instead prevents that data from being used to train Apple's large language models and other generative AI projects. It is, in essence, a bot to customize how another bot works.
Publishers can block Applebot-Extended by updating a text file on their websites known as the Robots Exclusion Protocol, or robots.txt. This file has governed how bots go about scraping the web for decades—and like the bots themselves, it is now at the center of a larger fight over how AI gets trained. Many publishers have already updated their robots.txt files to block AI bots from OpenAI, Anthropic, and other major AI players.
Robots.txt allows website owners to block or permit bots on a case-by-case basis. While there’s no legal obligation for bots to adhere to what the text file says, compliance is a long-standing norm. (A norm that is sometimes ignored: Earlier this year, a WIRED investigation revealed that the AI startup Perplexity was ignoring robots.txt and surreptitiously scraping websites.)
Applebot-Extended is so new that relatively few websites block it yet. Ontario, Canada–based AI-detection startup Originality AI analyzed a sampling of 1,000 high-traffic websites last week and found that approximately 7 percent—predominantly news and media outlets—were blocking Applebot-Extended. This week, the AI agent watchdog service Dark Visitors ran its own analysis of another sampling of 1,000 high-traffic websites, finding that approximately 6 percent had the bot blocked. Taken together, these efforts suggest that the vast majority of website owners either don’t object to Apple’s AI training practices are simply unaware of the option to block Applebot-Extended.
In a separate analysis conducted this week, data journalist Ben Welsh found that just over a quarter of the news websites he surveyed (294 of 1,167 primarily English-language, US-based publications) are blocking Applebot-Extended. In comparison, Welsh found that 53 percent of the news websites in his sample block OpenAI’s bot. Google introduced its own AI-specific bot, Google-Extended, last September; it’s blocked by nearly 43 percent of those sites, a sign that Applebot-Extended may still be under the radar. As Welsh tells WIRED, though, the number has been “gradually moving” upward since he started looking.
Welsh has an ongoing project monitoring how news outlets approach major AI agents. “A bit of a divide has emerged among news publishers about whether or not they want to block these bots,” he says. “I don't have the answer to why every news organization made its decision. Obviously, we can read about many of them making licensing deals, where they're being paid in exchange for letting the bots in—maybe that's a factor.”
Last year, The New York Times reported that Apple was attempting to strike AI deals with publishers. Since then, competitors like OpenAI and Perplexity have announced partnerships with a variety of news outlets, social platforms, and other popular websites. “A lot of the largest publishers in the world are clearly taking a strategic approach,” says Originality AI founder Jon Gillham. “I think in some cases, there's a business strategy involved—like, withholding the data until a partnership agreement is in place.”
There is some evidence supporting Gillham’s theory. For example, Condé Nast websites used to block OpenAI’s web crawlers. After the company announced a partnership with OpenAI last week, it unblocked the company’s bots. (Condé Nast declined to comment on the record for this story.) Meanwhile, Buzzfeed spokesperson Juliana Clifton told WIRED that the company, which currently blocks Applebot-Extended, puts every AI web-crawling bot it can identify on its block list unless its owner has entered into a partnership—typically paid—with the company, which also owns the Huffington Post.
Because robots.txt needs to be edited manually, and there are so many new AI agents debuting, it can be difficult to keep an up-to-date block list. “People just don’t know what to block,” says Dark Visitors founder Gavin King. Dark Visitors offers a freemium service that automatically updates a client site’s robots.txt, and King says publishers make up a big portion of his clients because of copyright concerns.
Robots.txt might seem like the arcane territory of webmasters—but given its outsize importance to digital publishers in the AI age, it is now the domain of media executives. WIRED has learned that two CEOs from major media companies directly decide which bots to block.
Some outlets have explicitly noted that they block AI scraping tools because they do not currently have partnerships with their owners. “We’re blocking Applebot-Extended across all of Vox Media’s properties, as we have done with many other AI scraping tools when we don’t have a commercial agreement with the other party,” says Lauren Starke, Vox Media’s senior vice president of communications. “We believe in protecting the value of our published work.”
Others will only describe their reasoning in vague—but blunt!—terms. “The team determined, at this point in time, there was no value in allowing Applebot-Extended access to our content,” says Gannett chief communications officer Lark-Marie Antón.
Meanwhile, The New York Times, which is suing OpenAI over copyright infringement, is critical of the opt-out nature of Applebot-Extended and its ilk. “As the law and The Times' own terms of service make clear, scraping or using our content for commercial purposes is prohibited without our prior written permission,” says NYT director of external communications Charlie Stadtlander, noting that the Times will keep adding unauthorized bots to its block list as it finds them. “Importantly, copyright law still applies whether or not technical blocking measures are in place. Theft of copyrighted material is not something content owners need to opt out of.”
It’s unclear whether Apple is any closer to closing deals with publishers. If or when it does, though, the consequences of any data licensing or sharing arrangements may be visible in robots.txt files even before they are publicly announced.
“I find it fascinating that one of the most consequential technologies of our era is being developed, and the battle for its training data is playing out on this really obscure text file, in public for us all to see,” says Gillham.
11 notes
·
View notes
Text
fundamentally you need to understand that the internet-scraping text generative AI (like ChatGPT) is not the point of the AI tech boom. the only way people are making money off that is through making nonsense articles that have great search engine optimization. essentially they make a webpage that’s worded perfectly to show up as the top result on google, which generates clicks, which generates ads. text generative ai is basically a machine that creates a host page for ad space right now.
and yeah, that sucks. but I don’t think the commercialized internet is ever going away, so here we are. tbh, I think finding information on the internet, in books, or through anything is a skill that requires critical thinking and cross checking your sources. people printed bullshit in books before the internet was ever invented. misinformation is never going away. I don’t think text generative AI is going to really change the landscape that much on misinformation because people are becoming educated about it. the text generative AI isn’t a genius supercomputer, but rather a time-saving tool to get a head start on identifying key points of information to further research.
anyway. the point of the AI tech boom is leveraging big data to improve customer relationship management (CRM) to streamline manufacturing. businesses collect a ridiculous amount of data from your internet browsing and purchases, but much of that data is stored in different places with different access points. where you make money with AI isn’t in the Wild West internet, it’s in a structured environment where you know the data its scraping is accurate. companies like nvidia are getting huge because along with the new computer chips, they sell a customizable ecosystem along with it.
so let’s say you spent 10 minutes browsing a clothing retailer’s website. you navigated directly to the clothing > pants tab and filtered for black pants only. you added one pair of pants to your cart, and then spent your last minute or two browsing some shirts. you check out with just the pants, spending $40. you select standard shipping.
with AI for CRM, that company can SIGNIFICANTLY more easily analyze information about that sale. maybe the website developers see the time you spent on the site, but only the warehouse knows your shipping preferences, and sales audit knows the amount you spent, but they can’t see what color pants you bought. whereas a person would have to connect a HUGE amount of data to compile EVERY customer’s preferences across all of these things, AI can do it easily.
this allows the company to make better broad decisions, like what clothing lines to renew, in which colors, and in what quantities. but it ALSO allows them to better customize their advertising directly to you. through your browsing, they can use AI to fill a pre-made template with products you specifically may be interested in, and email it directly to you. the money is in cutting waste through better manufacturing decisions, CRM on an individual and large advertising scale, and reducing the need for human labor to collect all this information manually.
(also, AI is great for developing new computer code. where a developer would have to trawl for hours on GitHUB to find some sample code to mess with to try to solve a problem, the AI can spit out 10 possible solutions to play around with. thats big, but not the point right now.)
so I think it’s concerning how many people are sooo focused on ChatGPT as the face of AI when it’s the least profitable thing out there rn. there is money in the CRM and the manufacturing and reduced labor. corporations WILL develop the technology for those profits. frankly I think the bigger concern is how AI will affect big data in a government ecosystem. internet surveillance is real in the sense that everything you do on the internet is stored in little bits of information across a million different places. AI will significantly impact the government’s ability to scrape and compile information across the internet without having to slog through mountains of junk data.
#which isn’t meant to like. scare you or be doomerism or whatever#but every take I’ve seen about AI on here has just been very ignorant of the actual industry#like everything is abt AI vs artists and it’s like. that’s not why they’re developing this shit#that’s not where the money is. that’s a side effect.#ai#generative ai
9 notes
·
View notes
Text
Time for a new edition of my ongoing vendetta against Google fuckery!
Hey friends, did you know that Google is now using Google docs to train it's AI, whether you like it or not? (link goes to: zdnet.com, July 5, 2023). Oh and on Monday, Google updated it's privacy policy to say that it can train it's two AI (Bard and Cloud AI) on any data it scrapes from it's users, period. (link goes to: The Verge, 5 July 2023). Here is Digital Trends also mentioning this new policy change (link goes to: Digital Trends, 5 July 2023). There are a lot more, these are just the most succinct articles that might explain what's happening.
FURTHER REASONS GOOGLE AND GOOGLE CHROME SUCK TODAY:
Stop using Google Analytics, warns Sweden’s privacy watchdog, as it issues over $1M in fines (link goes to: TechCrunch, 3 July 2023) [TLDR: google got caught exporting european users' data to the US to be 'processed' by 'US government surveillance,' which is HELLA ILLEGAL. I'm not going into the Five Eyes, Fourteen Eyes, etc agreements, but you should read up on those to understand why the 'US government surveillance' people might ask Google to do this for countries that are not apart of the various Eyes agreements - and before anyone jumps in with "the US sucks!" YES but they are 100% not the only government buying foreign citizens' data, this is just the one the Swedes caught. Today.]
PwC Australia ties Google to tax leak scandal (link goes to: Reuters, 5 July 2023). [TLDR: a Russian accounting firm slipped Google "confidential information about the start date of a new tax law leaked from Australian government tax briefings." Gosh, why would Google want to spy on governments about tax laws? Can't think of any reason they would want to be able to clean house/change policy/update their user agreement to get around new restrictions before those restrictions or fines hit. Can you?
SO - here is a very detailed list of browsers, updated on 28 June, 2023 on slant.com, that are NOT based on Google Chrome (note: any browser that says 'Chromium-based' is just Google wearing a party mask. It means that Google AND that other party has access to all your data). This is an excellent list that shows pros and cons for each browser, including who the creator is and what kinds of policies they have (for example, one con for Pale Moon is that the creator doesn't like and thinks all websites should be hostile to Tor).
#you need to protect yourself#anti google#anti chrome#anti chromium#chromium based browsers#internet security#current events#i recommend firefox#but if you have beef with it#here are alternatives!#so called ai#anti artificial intelligence#anti chatgpt#anti bard#anti cloud ai#data scraping
103 notes
·
View notes
Text
This day in history

On SEPTEMBER 24th, I'll be speaking IN PERSON at the BOSTON PUBLIC LIBRARY!

#20yrsago AnarchistU, Toronto’s wiki-based free school https://web.archive.org/web/20040911010603/http://anarchistu.org/bin/view/Anarchistu
#20yrsago Fair use is a right AND a defense https://memex.craphound.com/2004/09/09/fair-use-is-a-right-and-a-defense/
#20yrsago Bounty for asking “How many times have you been arrested, Mr. President?” https://web.archive.org/web/20040918115027/https://onesimplequestion.blogspot.com/
#20yrsago What yesterday’s terrible music https://www.loweringthebar.net/2009/09/open-mike-likely-to-close-out-legislators-career.htmlsampling ruling means https://web.archive.org/web/20040910095029/http://www.lessig.org/blog/archives/002153.shtml
#15yrsago Conservative California legislator gives pornographic account of his multiple affairs (including a lobbyist) into open mic https://www.loweringthebar.net/2009/09/open-mike-likely-to-close-out-legislators-career.html
#15yrsago Shel Silverstein’s UNCLE SHELBY, not exactly a kids’ book https://memex.craphound.com/2009/09/09/shel-silversteins-uncle-shelby-not-exactly-a-kids-book/
#10yrsago Seemingly intoxicated Rob Ford gives subway press-conference https://www.youtube.com/watch?v=WbcETJRoNCs
#10yrsago Amazon vs Hachette is nothing: just WAIT for the audiobook wars! https://locusmag.com/2014/09/cory-doctorow-audible-comixology-amazon-and-doctorows-first-law/
#10yrsago Dietary supplement company sues website for providing a forum for dissatisfied customers https://www.techdirt.com/2014/09/08/dietary-supplement-company-tries-suing-pissedconsumer-citing-buyers-agreement-to-never-say-anything-negative-about-roca/
#10yrsago New wind-tunnel tests find surprising gains in cycling efficiency from leg-shaving https://www.theglobeandmail.com/life/health-and-fitness/health/the-curious-case-of-the-cyclists-unshaved-legs/article20370814/
#10yrsago Behind the scenes look at Canada’s Harper government gagging scientists https://www.cbc.ca/news/science/federal-scientist-media-request-generates-email-frenzy-but-no-interview-1.2759300
#10yrsago Starred review in Kirkus for INFORMATION DOESN’T WANT TO BE FREE https://www.kirkusreviews.com/book-reviews/cory-doctorow/information-doesnt-want-to-be-free/
#10yrsago Steven Gould’s “Exo,” a Jumper novel by way of Heinlein’s “Have Spacesuit, Will Travel” https://memex.craphound.com/2014/09/09/steven-goulds-exo-a-jumper-novel-by-way-of-heinleins-have-spacesuit-will-travel/
#5yrsago Important legal victory in web-scraping case https://arstechnica.com/tech-policy/2019/09/web-scraping-doesnt-violate-anti-hacking-law-appeals-court-rules/
#5yrsago Whistleblowers out Falwell’s Liberty University as a grifty, multibillion-dollar personality cult https://web.archive.org/web/20190910000528/https://www.politico.com/magazine/amp/story/2019/09/09/jerry-falwell-liberty-university-loans-227914
#5yrsago Pinduoduo: China’s “Groupon on steroids” https://www.wired.com/story/china-ecommerce-giant-never-heard/
#5yrsago Notpetya: the incredible story of an escaped US cyberweapon, Russian state hackers, and Ukraine’s cyberwar https://www.wired.com/story/notpetya-cyberattack-ukraine-russia-code-crashed-the-world/
#5yrsago NYT calls for an end to legacy college admissions https://www.nytimes.com/2019/09/07/opinion/sunday/end-legacy-college-admissions.html
#5yrsago Purdue’s court filings understate its role in the opioid epidemic by 80% https://www.propublica.org/article/data-touted-by-oxycontin-maker-to-fight-lawsuits-doesnt-tell-the-whole-story
#1yrago Saturday linkdump, part the sixth https://pluralistic.net/2023/09/09/nein-nein/#everything-is-miscellaneous
The paperback edition of The Lost Cause, my nationally bestselling, hopeful solarpunk novel is out this month!
9 notes
·
View notes
Text
How Web Scraping Helps In Extracting Government And Public Sector Data?

Along with the growth in technology, big data and analytics are undeniably no less crucial these days. It applies to business companies, healthcare, and the administration. Web scraping is the process of harvesting essential data from the internet reservoir; therefore, it can obtain this vital information. Changing public sector and government research science requires better data for decision-makers to make the right choices, and these are people like policymakers and analysts, among others. However, on digital platforms, a lot of information is generated, which needs to be clarified when trying to filter or sort it all out. Therefore, web scraping provides a means of collecting data more efficiently and making research more creative and rapidly performed.
What is Government and Public Data Scraping?
Data scraping, or web scraping, is using a digital tool to collect information from websites and online databases automatically. Dream of no more need to visit websites to copy all important data – let a robot do it. This tool collects data from websites like government rules, public reports, or price tags. People utilize data scraping for research purposes, such as examining legislation or analyzing market patterns. It is an excellent way to get information rapidly (all you need to understand various topics) and use it to understand any subject better.
Nevertheless, a handful of points are worth considering when performing web scraping government sites. It is essential to follow the rules and laws about using online information. For instance, certain websites may not allow scraping; thus, you should adhere to them by any means. Furthermore, we must handle personal data cautiously and avoid undesired behaviors as much as possible. So, while data scraping is an effective tool, it must be used safely and politely.
Scraping Data from Government Sources
Scraping government website data means using special tools or programs to collect information from official government websites, databases, or online portals. Government bodies, such as data storehouses, are especially information-supplier entities, such as laws, public records, budgets, and statistics. Without that data, data scientists and analysts, which are not customer-friendly for regular people, can be equipped with vital information, monitor the government, and check public policies and efficiency.
Scraping government websites involves retrieving data from data providers or sources such as government websites.
Summary
What Kind of Data Can You Get From Government Websites:
Laws and Rules: This includes the texts of laws, rules, and policies.
Public Records: Things like birth certificates, property ownership, and court case details.
Financial Data: Budgets, economic stats, and tax details.
People and Society: Census info, health numbers, and education stats.
Environment: Weather data, pollution info, and maps.
Public Opinion: Surveys, polls, and comments from the public.
From Public Organizations
Business Data: Details about registered businesses and professional licenses.
Regulatory Docs: Reports and documents that businesses have to submit.
Safety and Infrastructure: Crime rates, emergency services, and transportation details.
Types of Data Scraped from Government Websites
Remember, the kind of data you can find might differ depending on where you are or which part of the government you're looking at. When obtaining data from various sources, adhering to any restrictions or norms is critical.
Laws and Rules
Laws and Regulations: These are like the rulebooks that the government follows. They contain the actual texts of laws and rules that the government sets.
Policy Papers: These act as the government's master data. They're official documents outlining the government's intentions and strategies for addressing various issues.
Property Records: These records tell us about properties in an area, such as who owns them, how much they're worth, and how they're being used.
Court Records: This is information about legal cases, like who's involved, what the case is about, and when the court dates are.
Money Matters
Budgets and Spending: Those documents basically show us where the government plans to spend its money. Allocation of funds, detailing expenditures on sectors such as education, infrastructure, and healthcare while also disclosing the destinations of the funds.
Economic Stats: As for economic stats, they are a quick outline of how the economy is doing. They tell us if people find jobs easily and if prices are going up or down. It's a way to see if the economy is healthy or if some problems need fixing.
Taxes: Here, you can find information about how much tax people and businesses have to pay, what forms they need to fill out, and any rules about taxes.
People and Society
Census Data: This gives us information about the people living in a place, like how many people live there, their ages, and other demographics.
Health Stats: These tell us about people's health, such as whether there's a lot of flu or how many people have been vaccinated.
Education: This part tells us about schools, including how students are doing in their classes, how many students graduate, and what resources the schools have.
Climate Info: This is all about the weather and climate in an area, such as whether it's usually hot or cold or if it rains a lot
Environmental Assessments: These give us details about the environment, like how clean the air and water are and if there are any protected areas.
Maps and Geospatial Data: These are digital maps that show where things are located, such as parks, roads, or buildings.
Public Opinion
Surveys and Polls: These are questionnaires that ask people what they think about different things. They might ask who they voted for in an election or what they think about a new law. It is a way for people to share their opinions and for others to understand what's important to them.
Public Comments: This is feedback from people about government plans or projects. It's like when people write to say what they think about a new road or park.
Business Licenses: This tells us about businesses in an area, like what they do and if they have the proper licenses to operate.
Professional Licenses: These are licenses that people need to work in specific jobs, like doctors or lawyers.
Regulatory Info: This is paperwork that businesses or organizations have to fill out to show they're following the rules set by the government.
Crime Stats: This tells us about crime in an area, such as how many crimes are happening and what kind.
Emergency Services: This is information about services like fire departments or ambulances, like how quickly they respond to emergencies.
Transport Info: This gives us details about getting around, like traffic conditions or bus schedules.
Infrastructure: This is about public projects like building roads or schools, telling us what's being built and when it will be done.
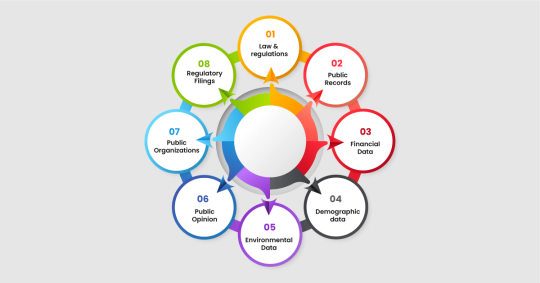
Scraping Data from the Public Sector

Scraping data from the public sector is collecting information from government websites or sites that receive money from the government. This information can be helpful for researching, public sector data analytics, or ensuring that things are open and transparent for everyone. Businesses scrape public sector data to stay updated with the latest updates.
By scraping different types of data from the public sector, researchers, analysts, or even regular people can learn a lot, make better decisions, perform public sector data analytics, and monitor what the government and public organizations are doing.
Laws and Regulations
Texts of Laws, Regulations, and Policies: This is where you can find the actual words of laws made by the government. It also includes rules and plans for different areas like traffic, environment, or health.
Public Records
Vital Records: These are essential papers that tell us about significant events in people's lives, such as when they were born, married, passed away, or divorced.
Property Records: These data tell you about properties, such as who owns them, how much they're worth, and what they're used for.
Court Records: This is information about legal cases, court decisions, and when the next court dates are.
Financial Data
Budgets: These plans show how the government will spend money on different things.
Economic Indicators: These are data that tell us how well the economy is doing, such as whether people have jobs or if prices are going up.
Tax Information: This is about taxes, like how much people or businesses have to pay and how the government uses that money.
Demographic Data
Census Data: This is information from the national headcount of people, showing things like age, where people live, and family size.
Health Statistics: This is data about health issues, like outbreaks, vaccination rates, or hospitals.
Education Data: This tells us about schools, how well students are doing, and what resources are available.
Environmental Data
Climate Information: This is about the weather and climate, like temperatures or weather patterns.
Environmental Assessments: These are studies about how people affect the environment, pollution, and efforts to protect nature.
Geospatial Data: This is like digital maps showing geographical information, like boundaries or landmarks.
Public Opinion
Surveys and Polls: These are the results of asking people questions to determine their thoughts on different topics.
Public Comments: People's feedback or opinions on government plans or projects.
Public Organizations
Business Licenses: This is information about businesses, such as their name, address, type, and whether they have a license.
Professional Licenses: This is about licenses for jobs like doctors, lawyers, or engineers, showing if they're allowed to practice and if they've had any issues.
Regulatory Filings
Professional Licenses: This is about licenses for jobs like doctors, lawyers, or engineers, showing if they're allowed to practice and if they've had any issues.
Reports and Documents: These are papers or reports that businesses or people have to give to certain government agencies, like financial reports or environmental studies.
Crime Statistics: These data tell us about crime, such as the amount or types of crimes committed.
Emergency Services Data: This is information about services like fire or ambulance services, such as how quickly they respond to emergencies.
Transportation Information: This tells us about getting around, like traffic, roads, public transit, or significant construction projects.
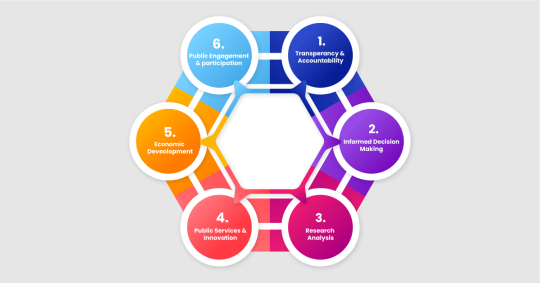
Benefits of Web Scraping in the Government and Public Sector

Companies should be responsible enough to choose the data they believe brings greater value to a specific context at that time. There are various benefits of web scraping government sites and public sector data:
Transparency and Accountability
When we perform web scraping government sites, we can see what the government is doing more clearly. Government and public sector data analytics helps keep them accountable because people can see where money is being spent and what decisions are being made.
Informed Decision-Making
Businesses scrape government websites and public sector data to get access to large datasets that help researchers, policymakers, and businesses make better decisions. For example, they can determine whether a new policy is working or understand economic trends to plan for the future.
Research and Analysis
The modern approach to scrape public sector data and government website data can be utilized by professionals and scientists to learn more about health, education, and the environment. This allows us to learn more about these subjects and identify ways to enhance them.
Public Services and Innovation
With public sector data analytics and web scraping government sites, developers can create new apps or sources of information that make life easier for people. For example, maps showing public transportation routes or directories for community services.
Economic Development
Businesses can use government economic data to make plans by ensuring success of their business. This can attract more investment because investors can see where there are good opportunities.
Public Engagement and Participation
When businesses extract public sector data and government website data, People can join conversations about community matters when they can easily understand government information. This makes democracy stronger by letting more people share their thoughts and shape what happens in their area.
Conclusion
Web scraping is increasingly seen as a valuable tool for extracting data, particularly as governments and public sectors adapt to the digital era. One of the most critical factors in current governance is no longer the line about open data projects with performing web scraping government sites.
Collaborating with enterprises data scraping like iweb Scraping is the way toward a future course of events where data-driven governance is the leading force. Thus, the public sector is more informed, transparent, and accountable. Scraping data from the internet can be viewed as a powerful tool for governmental institutions that enables them to collect a massive amount of essential information in a relatively short time. To put it categorically, web scraping is a valuable tool that the government should embrace as its friend. Companies that collect data, like iWeb Scraping services, are at the forefront of innovation and provide improved and new methods of data collecting that benefit all parties. Nevertheless, some challenges can come up often, but this web scraping company remains relevant to the government and public sector institutions during their data scraping process. The process of scraping public sector data and government websites is gathered with diligence and ethical consideration to help policymakers make more informed decisions and improve their services.
0 notes
Text
Algorithm is not a bad word
Named for Arabic mathematician al-Khwarizmi and partially formalized by queer mathematician Alan Turing, algorithms are simply a process for doing things, potentially with a desired result.
An early algorithm we learn in school is how to add two whole numbers together. Using pencil and paper, you can probably figure out what 420 + 69 is. In fact there are multiple ways. You could draw out 420 dots, draw another 69 dots, and count how many there are in total. Or you could lay them vertically, start at the ones column, and compute the digits of the sum.
Algorithms are not strictly related to numbers. What if you’re a teacher and you want to sort homework assignments alphabetically by the students’ names? Well you’ll probably have a process, which involves checking repeatedly if two pieces of homework are out of order (e.g. if you had homework from Bob then homework from Alice, you would swap the two since Alice is first alphabetically).
Another great non-numerical example of algorithms is solving the Rubik’s Cube and it’s larger variants. In the cube solving community, there are algorithms for specific processes, such as rotating corners cubies or flipping edge cubies. Some of these apply to the 3x3x3 cube, others can be generalized to help one solve a 69x69x69 cube.
Algorithms are also beautiful. Visualizing how the data dances around can be incredible. Check out this animation from Wikipedia showing the Heapsort algorithm in action:

This inspired the hell outta me when I first saw it in 2007. That diagram a couple seconds in, where it just sounds like it’s emitting a thunky beep at ya before suddenly just putting everything together. The way there’s sort of a pattern before it. Just that sheer magic.
You can also make art out of algorithms. From my username, one of my favorite categories is maze generation algorithms. Think Labyrinth, whose algorithm page I just linked, was an early website I found on the Internet, and I’m so happy it has survived the various eras of web evolution. The Maze of Theseus in particular was a huge inspiration for me after printing it out in 2000 on a summer road trip.

Alas Think Labyrinth is from before the days of heavy animations on the Internet, so to visualize a maze algorithm I will instead link to Mike Bostock’s article on Visualizing Algorithms. It includes many dynamic animations that are rendered in your browser, including the sorting algorithms and maze generation algorithms mentioned above, among many others.
So why the hate for algorithms?
On Tumblr in the past few days, and more generally social media in the past decade, we recently saw favoritism for sorting algorithms that allow us to view our feeds in chronological order. Many claimed they were opposed to an algorithm that decided in a corporate-specific manner what we should see first. Let me be clear: the corporate ordering of a feed is bad, but it is not bad because it’s an algorithm. It’s bad because it’s not one of the algorithms that users want for ordering their feed.
The other negative use case grew heavily in the past 15 years: algorithms that are “trained” on biased and/or unethically obtained data. We’ve seen many examples of systems that were trained on data sets of white college students such as facial recognition technology, which then later gets implemented at a large scale and fucks over people of color. The past couple years we’ve seen a rise in creating data sets based on scraping millions of artists’ works without any permission from the artists themselves*. Either of these applied to a corporate or government scale leads to active harm to populations already at risk and probably some new ones too.
Finally, we’ve seen a rise in computer automation for things that should be done by people. I can’t find the specifics, but this quote is allegedly from a 1979 IBM presentation:
A computer can never be held accountable, therefore a computer must never make a management decision.
My first thought on where this comes up is applying for jobs. Many companies will use a poorly thought out algorithm to filter through job applications, simply scanning for a couple key words they want (programmers who know Vulkan or Node.js) or more maliciously looking for words they don’t want (needing any kind of accommodation, sounding too anti-capitalist, etc). These algorithms cannot be held accountable and should not be involved in any stage of the hiring process.
Quick aside: When I was searching for the source of that quote about accountability, I typed in the first half in Google, and the autocomplete was

Fucking modern Google.
Some concluding thoughts
I like algorithms. They are a passion of mine. When people say algorithms are evil, I’m sad. When people recognize the usage of certain algorithms in certain contexts are evil, I’m more happy (yet still disturbed these things happen). I just really wanted to educate people on the usage of the word.
Also, algorithms are not about Al Gore’s dance moves. Please stop with that stupid fucking joke.
*I mentioned scraping data from millions of images without permission of the creators. My one iffy status with this is how sort of applies to the human brain doing a similar process over the span of one’s life. What is it that separates my looking through a book of Escher’s works from a computer looking at it?
Obviously many things, but I’m horrendous as philosophy and ethics, so I’m just gonna stay in my comfort zone of pure algorithms and try not to get too involved. Experts can figure out a more formal definition for what I can only describe as a gut feeling.
13 notes
·
View notes
Text
It's worse.
The glasses Meta built come with language translation features -- meaning it becomes harder for bilingual families to speak privately without being overheard.
No it's even worse.
Because someone has developed an app (I-XRAY) that scans and detects who people are in real-time.
No even worse.
Because I-XRAY accesses all kinds of public data about that person.
Wait is it so bad?
I-XRAY is not publicly usable and was only built to show what a privacy nightmare Meta is creating. Here's a 2-minute video of the creators doing a experiment how quickly people on the street's trust can be exploited. It's chilling because the interactions are kind and heartwarming but obviously the people are being tricked in the most uncomfortable way.
Yes it is so bad:
Because as satirical IT News channel Fireship demonstrated, if you combine a few easily available technologies, you can reproduce I-XRAYs results easily.
Hook up an open source vision model (for face detection). This model gives us the coordinates to a human face. Then tools like PimEyes or FaceCheck.ID -- uh, both of those are free as well... put a name to that face. Then phone book websites like fastpeoplesearch.com or Instant Checkmate let us look up lots of details about those names (date of birth, phone #, address, traffic and criminal records, social media accounts, known aliases, photos & videos, email addresses, friends and relatives, location history, assets & financial info). Now you can use webscrapers (the little programs Google uses to index the entire internet and feed it to you) or APIs (programs that let us interface with, for example, open data sets by the government) -> these scraping methods will, for many targeted people, provide the perpetrators with a bulk of information. And if that sounds impractical, well, the perpetrators can use a open source, free-to-use large language model like LLaMa (also developed by Meta, oh the irony) to get a summary (or get ChatGPT style answers) of all that data.
Fireship points out that people can opt out of most of these data brokers by contacting them ("the right to be forgotten" has been successfully enforced by European courts and applies globally to people that make use of our data). Apparently the New York Times has compiled an extensive list of such sites and services.
But this is definitely dystopian. And individual opt-outs exploit that many people don't even know that this is a thing and that place the entire responsibility on the individual. And to be honest, I don't trust the New York Times and almost feel I'm drawing attention to myself if I opt out. It really leaves me personally uncertain what is the smarter move. I hope this tech is like Google's smartglasses and becomes extinct.
i hate the "meta glasses" with their invisible cameras i hate when people record strangers just-living-their-lives i hate the culture of "it's not illegal so it's fine". people deserve to walk around the city without some nameless freak recording their faces and putting them up on the internet. like dude you don't show your own face how's that for irony huh.
i hate those "testing strangers to see if they're friendly and kind! kindness wins! kindness pays!" clickbait recordings where overwhelmingly it is young, attractive people (largely women) who are being scouted for views and free advertising . they're making you model for them and they reap the benefits. they profit now off of testing you while you fucking exist. i do not want to be fucking tested. i hate the commodification of "kindness" like dude just give random people the money, not because they fucking smiled for it. none of the people recording has any idea about the origin of the term "emotional labor" and none of us could get them to even think about it. i did not apply for this job! and you know what! i actually super am a nice person! i still don't want to be fucking recorded!
& it's so normalized that the comments are always so fucking ignorant like wow the brunette is so evil so mean so twisted just because she didn't smile at a random guy in an intersection. god forbid any person is in hiding due to an abusive situation. no, we need to see if they'll say good morning to a stranger approaching them. i am trying to walk towards my job i am not "unkind" just because i didn't notice your fucked up "social experiment". you fucking weirdo. stop doing this.
19K notes
·
View notes
Photo


The BBC is threatening to take legal action against an artificial intelligence (AI) firm whose chatbot the corporation says is reproducing BBC content "verbatim" without its permission.The BBC has written to Perplexity, which is based in the US, demanding it immediately stops using BBC content, deletes any it holds, and proposes financial compensation for the material it has already used.It is the first time that the BBC - one of the world's largest news organisations - has taken such action against an AI company.In a statement, Perplexity said: "The BBC's claims are just one more part of the overwhelming evidence that the BBC will do anything to preserve Google's illegal monopoly."It did not explain what it believed the relevance of Google was to the BBC's position, or offer any further comment.The BBC's legal threat has been made in a letter to Perplexity's boss Aravind Srinivas."This constitutes copyright infringement in the UK and breach of the BBC's terms of use," the letter says.The BBC also cited its research published earlier this year that found four popular AI chatbots - including Perplexity AI - were inaccurately summarising news stories, including some BBC content.Pointing to findings of significant issues with representation of BBC content in some Perplexity AI responses analysed, it said such output fell short of BBC Editorial Guidelines around the provision of impartial and accurate news."It is therefore highly damaging to the BBC, injuring the BBC's reputation with audiences - including UK licence fee payers who fund the BBC - and undermining their trust in the BBC," it added.Web scraping scrutinyChatbots and image generators that can generate content response to simple text or voice prompts in seconds have swelled in popularity since OpenAI launched ChatGPT in late 2022.But their rapid growth and improving capabilities has prompted questions about their use of existing material without permission.Much of the material used to develop generative AI models has been pulled from a massive range of web sources using bots and crawlers, which automatically extract site data. The rise in this activity, known as web scraping, recently prompted British media publishers to join calls by creatives for the UK government to uphold protections around copyrighted content.In response to the BBC's letter, the Professional Publishers Association (PPA) - which represents over 300 media brands - said it was "deeply concerned that AI platforms are currently failing to uphold UK copyright law." It said bots were being used to "illegally scrape publishers' content to train their models without permission or payment."It added: "This practice directly threatens the UK's £4.4 billion publishing industry and the 55,000 people it employs."Many organisations, including the BBC, use a file called "robots.txt" in their website code to try to block bots and automated tools from extracting data en masse for AI.It instructs bots and web crawlers to not access certain pages and material, where present.But compliance with the directive remains voluntary and, according to some reports, bots do not always respect it.The BBC said in its letter that while it disallowed two of Perplexity's crawlers, the company "is clearly not respecting robots.txt".Mr Srinivas denied accusations that its crawlers ignored robots.txt instructions in an interview with Fast Company last June.Perplexity also says that because it does not build foundation models, it does not use website content for AI model pre-training.'Answer engine'The company's AI chatbot has become a popular destination for people looking for answers to common or complex questions, describing itself as an "answer engine".It says on its website that it does this by "searching the web, identifying trusted sources and synthesising information into clear, up-to-date responses".It also advises users to double check responses for accuracy - a common caveat accompanying AI chatbots, which can be known to state false information in
0 notes
Text
Internal dissent within the mostly volunteer disease-news network known as ProMED—which alerted the world to the earliest cases of Covid, Middle East Respiratory Syndrome (MERS), and SARS—has broken out into the open and threatens to take down the internationally treasured network unless an external sponsor can be found.
The struggle for the future of the low-tech site, which also sends out each piece of content on a no-reply email list with 20,000 subscribers, has been captured in dueling posts to its front page. On July 14, a post by ProMED’s chief content officer, a veterinarian and infectious-disease expert named Jarod Hanson, announced that ProMED is running out of money. Because it is being undermined by data-scraping and reselling of its content, Hanson wrote, ProMED would turn off its RSS and Twitter feeds, limit access to its decades of archives to the previous 30 days, and introduce paid subscriptions.
Hanson is at the top of ProMED’s masthead, and the post was signed “the ProMED team,” which gave the announced changes the feeling of a united action. That turned out not to be the case. Very early on August 3, a post addressing “Dear friends and readers of ProMED” appeared on the site’s front page. The open letter was signed by 21 of its volunteer and minimally paid moderators and editors, all prominent physicians and researchers, and it makes clear that no unity existed.
“Although the [July post] was signed by ‘The ProMED Team,’ we the undersigned want to assure you that we had no prior knowledge,” the open letter stated. “With great sadness and regret … we, the undersigned, are hereby suspending our work for ProMED.”
The letter was taken off the site within a few hours, but the text had already been pushed to email subscribers. (WIRED’s copy is here.) On Friday, signers of the open letter said they had been locked out of the site’s internal dashboard. The site’s regular rate of posting slowed Friday and Saturday, but appeared to pick up again on Sunday.
Maybe this sounds like a small squabble in a legacy corner of the internet—but to public health and medical people, ProMED falling silent is deeply unnerving. For more than 20 years, it has been an unmissable daily read, ever since it received an emailed query in February 2003 about chat-room rumors of illnesses near Hong Kong. As is the site’s practice, that initial piece of intel was examined by several volunteer experts and cross-checked against a separate piece of news they found online. In its post, which is not currently accessible, ProMED reproduced both the email query and the corroborating information, along with a commentary. That post became the first news published outside China of the burgeoning epidemic of SARS viral pneumonia, which would go on to sweep the world that spring and summer—and which was acknowledged by the regional government less than 24 hours afterward.
Using the same system of tips and local news sources, combined with careful evaluation, ProMED published the first alerts of a number of other outbreaks, including two more caused by novel coronaviruses: MERS and Covid, which was detected via two online articles published by media in China on December 30, 2019. Such alerts also led the World Health Organization to reconsider what it will accept as a trustworthy notice of the emergence of epidemics. When the organization rewrote the International Health Regulations in the wake of SARS, committing member nations to a public health code of conduct, it included “epidemic intelligence from open sources” for the first time.
On the surface, the dispute between ProMED’s moderators and its leadership team—backed by the professional organization that hosts the project, the International Society for Infectious Diseases (ISID)—looks like another iteration of a discussion that has played out online for years: how to keep publishing news if no one wants to pay for it. But while that is an enduring problem, the question posed by the pause in ProMED’s operations is bigger than subscriptions. It looks more like this: How do you make a case for the value of human-curated intelligence in a world that prefers to pour billions into AI?
“ProMED might not always be the fastest, but it always provides important context that would not come through a news report,” says John Brownstein, an epidemiologist and chief innovation officer at Boston Children’s Hospital, who cofounded the automated online outbreaks database HealthMap and has collaborated with ProMED. “It’s the anti-social media, in a way. It’s a trusted voice.”
“ProMED possesses trained scientists that are able to discern what is really a problem and what is fake news,” says Scott J. N. McNabb, a research professor at Emory University’s Rollins School of Public Health and a former chief of public health surveillance at the US Centers for Disease Control and Prevention. “That's a tremendous advantage. So the reports are not coming from uninformed individuals, they're coming from professionals that have the medical expertise and public health expertise to really discern: ‘Is this genuine or not?’”
To understand why the fate of ProMED feels momentous, it helps to know a little bit about its history. The deliberately Web 1.0 site—it has no comment section and runs no graphics, so as not to stress the bandwidth in low-income nations—was created in 1994 and began being hosted by ISID in 1999. Its chief founder was the late John Payne Woodall, an entomologist and virologist who had a hand in most of the post-World War II build-up of global public health infrastructure, working for the Rockefeller Foundation, the WHO, and the CDC. (Cofounders were Stephen Morse, a professor of epidemiology at Columbia University’s Mailman School of Public Health, and Barbara Hatch Rosenberg, a biological weapons expert and former professor of microbiology at SUNY Purchase.)
Woodall believed that everyday people’s reports of events could constitute important early warnings of looming problems. The value of open source intelligence might seem obvious today, with every movement of the war in Ukraine, for instance, tracked on Twitter. But at the time, Woodall was challenging the accepted view that official public health surveillance data, gathered by governments and nongovernmental entities, was the key to understanding the havoc diseases can create. And he was leveraging early civilian access to the internet to do it. The site was established and scored its momentous early success exposing SARS all before Twitter launched and Facebook opened to the general public in 2006, and before the first iPhone went on sale in 2007.
The arrival of social media made it possible to instantly share information on all kinds of emergencies, from the Arab Spring to the Fukushima nuclear disaster to the Ebola epidemic in West Africa, and many accounts built audiences and monetization by conveying real-time alerts on arrays of subjects, often with no sourcing attached. The speed of Twitter (now known as X) could make ProMED’s careful verification look slow; though the organization pushed its content to its own Twitter account, those posts would often arrive after a breaking-news account got there first.
That left the site in a battle for funding. Its online host ISID lost revenue during the pandemic, as professionals stayed home from the conferences it had hosted. Internally, money began to dry up. One of the complaints aired in the open letter is that payments to the moderators, who receive a small stipend, are already in arrears and will be delayed for two more months.
“We are really up against a challenge of long-term, sustainable funding for operating ProMED,” says ISID’s CEO, Linda MacKinnon, who described the organization as sipping from project grants to keep core operations going on a budget of about $1 million a year. (MacKinnon spoke after the July 14 announcement but before the open letter was published.) “We have sort of grown organically over the years, from project to project that were all cobbled together, but not stepping back and putting together a business case of how to sustain, how to innovate. We have found ourselves partnering or collaborating with hospitals and academic institutions, but [not finding a] long-term home.”
Hanson, who published the post outlining the changes, told WIRED by email Friday evening: “Not a single entity has stepped forward with any type of funding to allow ProMED to continue to operate as it has for 28 years, which is to say open and free to the public. We have diligently pursued funding and messaged our plan for the past year and made our financial situation widely known.” He added, “Funders are primarily interested in the latest and greatest tools, so from their strategic perspective there's little value in ProMED—an aging but highly effective email surveillance system—to show to their leadership/benefactors.”
A deeper look at recent history shows that the battle over ProMED is not only about money, no matter how critical that might be. After Woodall, ProMED was led for years by Larry Madoff, an infectious disease physician and professor at the University of Massachusetts Medical School who built a wide network of collaborators. Madoff was abruptly dismissed by ISID two years ago, and both he and moderators who worked with him say they do not know why. MacKinnon will only say the action was “a board decision.” Madoff held the title of editor in chief; according to the site’s team listings, that title is not now in use.
Asked for comment, Madoff said this: “ProMED is a public good, and it ought to be freely available and remain so. It would be a shame if it lost large segments of its audience, many of whom are in low-resource settings, because of a failure of the parent organization to adequately provide resources.” He added: “Losing subscribers will hobble ProMED because it depends on its readers to send information. By not having that big subscriber base, by restricting your base through a paid model, you’re going to lose that.”
In 2020, Madoff told WIRED the site’s subscriber base was about 83,000 addresses (which cannot now be confirmed), whereas MacKinnon’s team set the current count at about 20,000. The open letter, among other demands, asks ISID to “ensure the administrative and editorial independence of ProMED's content and subscription policies. This could largely be accomplished by restoring a true Editor-in-Chief position with independent executive authority.”
WIRED reached out to all 21 signatories of the open letter to verify that it is authentic. As of Monday, six—Marjorie P. Pollack, Leo Liu, Maria Jacobs, Martin Hugh-Jones, Pablo M. Beldomenico, and Thomas Yuill—confirmed that it represents their views. “In the first six months of Covid, I averaged three hours of sleep a night,” says Pollack, an infectious disease physician who first joined the site in 1997, and wrote the December 30, 2019 post that first flagged the emergence of Covid. “We have been a collegial group of people, and we understood that ProMED represented a labor of love.”
Asked for comment on the open letter, MacKinnon emailed a statement Friday afternoon that was also posted to the ProMED site. ”We recognize that members of the ProMED community are concerned about the continuation of the platform,” it says in part. “We also know that we could have communicated changes more clearly to the community and apologize for any confusion and distress caused.” The statement went on to enumerate the site’s financial challenges and ended with a plea for “unrestricted operational funding and investment.”
The irony is that ProMED may have run out of runway just as past obstacles to its growth begin to evaporate. Unmeasured but apparently substantial portions of medical and public health users have departed Twitter following the shifts in its ownership and politics, and none of its replacements—Mastodon, Bluesky, Threads, or others—have accumulated the velocity or density to match. That could allow a revived ProMED to reestablish its utility as a trusted source that deserves broader support. But as even ProMED insiders acknowledge, that will need some kind of partner. Last week, supporters said they were hoping to lobby major public health graduate schools, or even the WHO’s new Hub for Pandemic and Epidemic Intelligence, based in Berlin, to lend ProMED financial support or a new institutional home.
“ProMED needs to be saved,” McNabb says. “We can move it into an academic setting, or into a broader context like a WHO collaborating center—wherever people feel comfortable and it can be funded appropriately. But we need to save it. It’s too important for public health.”
4 notes
·
View notes
Text
Lawyer Profiles Data Extraction by Lawyersdatalab.com

Lawyer Profiles Data Extraction by Lawyersdatalab.com
In the competitive legal industry, effective marketing strategies are crucial for law firms to stay ahead. One of the most valuable resources for these strategies is an accurate and comprehensive list of lawyer profiles. Lawyersdatalab.com specializes in Lawyer Profiles Data Scraping, providing law firms and legal marketing companies with detailed and up-to-date attorney information. This service is designed to support law firm marketing, lawyers marketing, and legal marketing companies in their efforts to connect with the right professionals and potential clients.
List of Data Fields
Our Lawyer Profiles Data Scraping service collects a wide range of data fields to ensure you have all the necessary information for your marketing campaigns. These data fields include:
- Full Name
- Contact Information
- Professional Title
- Law Firm Details
- Specialization Areas
- Years of Experience
- Social Media Profiles
Benefits of Lawyer Profiles Data Scraping
Targeted Marketing Campaigns
With a detailed and accurate list of lawyer profiles, law firms and legal marketing companies can create highly targeted marketing campaigns. By focusing on specific areas of expertise and practice, marketing efforts become more effective, reaching the right audience with relevant messages. This increases the likelihood of engagement and conversion, ultimately leading to more successful marketing outcomes.
Enhanced Networking Opportunities
Access to comprehensive lawyer profiles facilitates networking opportunities within the legal community. Law firms can connect with other professionals for potential collaborations, referrals, and partnerships. Legal marketing companies can leverage this information to build stronger relationships and foster connections that can lead to new business opportunities.
Cost-Effective Marketing
Targeted email campaigns reduce wastage of resources and ensure that marketing messages reach the intended recipients. This not only improves the efficiency of marketing efforts but also enhances the return on investment.
Improved Client Acquisition
Having access to detailed lawyer profiles enables law firms to identify and reach out to potential clients more effectively. By understanding the specific needs and interests of their target audience, firms can tailor their marketing strategies to address these needs, leading to improved client acquisition and retention.
Targeted Lawyers Email List Based On Specialization
List of Criminal Lawyers
Wyoming Lawyers Email List
Family Lawyers Email List
Email List of Government Lawyers
General Practice Attorneys Email Database
Tax Attorney Mailing List
Nebraska Lawyers Email List
Massachusetts Lawyers Email List
Employment Lawyer List
Database of Property Law Lawyers
Washington Lawyers Email List
Nevada Lawyers Email List
Best Lawyer Profiles Data Extraction in USA
Washington D.C., Nashville, Honolulu, Houston, Philadelphia, Oklahoma City, Dallas, Austin, New York, Colorado, Orlando, Miami, Boston, Seattle, Columbus, El Paso, Louisville, Fresno, Charlotte, Atlanta, San Diego, Phoenix, Sacramento, Las Vegas, San Antonio, Baltimore, Virginia Beach, Jacksonville, Portland, Albuquerque, Fort Worth, Wichita, New Orleans, Denver, Chicago, Kansas City, Indianapolis, Arlington, Detroit, Tulsa, Long Beach, Raleigh, San Jose, Memphis, Bakersfield, San Francisco, Tucson, Los Angeles, Omaha, Springs, Milwaukee and Mesa.
Conclusion
By providing comprehensive and accurate attorney information, this service supports targeted marketing campaigns, enhances networking opportunities, and improves client acquisition efforts. Investing in a reliable data scraping service ensures that your marketing strategies are effective, efficient, and successful. Contact Lawyersdatalab.com today to learn more about how our Lawyer Profiles Data Scraping service can benefit your legal marketing efforts.
Website: Lawyersdatalab.com
Email: [email protected]
#lawyerprofilesdataextraction#lawyerprofilesdatascraping#attorneyprofilesdataextraction#lawyersdatalab#lawyersemaillist#lawyersemaildatabase#lawfirmemaillist
0 notes